
Imagine an employee opens your company's internal HR assistant and asks a simple question: "What is the salary of an SDE 2 here?" Within seconds, the AI responds with a detailed summary that includes actual employee compensation data across the organization.
No security controls were bypassed. No database was breached. The system simply retrieved information it should never have exposed in the first place.
This is one of the most important security challenges facing enterprise AI deployments. Retrieval-Augmented Generation (RAG) systems excel at finding relevant information across vast collections of documents, spreadsheets, and knowledge repositories. Yet access control remains one of the biggest gaps in AI security, with 97% of AI-related security breaches involving systems that lacked proper authorization controls.
Without fine-grained authorization (FGA) integrated into the retrieval process, the system has no reliable way to distinguish between information that is relevant and information that the user is actually authorized to access.
This article explains why the retrieval layer is the real security boundary in modern RAG architectures, where traditional role-based access controls break down, and how fine grained authorization prevents unauthorized data from ever entering the LLM's context window.
The Salary Spreadsheet Problem: When Helpful AI Becomes a Privacy Violation
A company rolls out an internal assistant connected to HR docs, project wikis, compensation sheets, and policy files. The objective is straightforward. Employees should get answers faster without searching through folders or waiting on HR.
Then someone asks a direct question about compensation.
The RAG pipeline does exactly what it was built to do. It searches the vector database, finds the compensation spreadsheet because it is highly relevant, retrieves the matching rows, and hands that context to the LLM. The model summarizes the rows and returns the answer.
At no point did the system “hack” anything. It retrieved what it had access to retrieve. The failure was architectural. The retrieval layer had no enforcement boundary, so fine-grained authorization control did not exist where it mattered.
“The AI did not leak the data. The RAG pipeline retrieved it. The distinction matters: you cannot fix a retrieval problem with a generation-layer filter.”
That is the real issue. The LLM is not the problem. The retrieval layer had no authorization controls, so it treated semantically relevant data as if it were authorized data. Those are not the same thing, and in a RAG system that difference decides whether the assistant is helpful or a privacy violation.
How RAG Actually Works
Think of RAG as a research assistant who has read every document in your filing cabinet. You ask a question, and the assistant quickly runs to the cabinet, pulls out the most relevant pages, and reads them back to you. It is fast, accurate, and useful.
But if that cabinet contains both “CONFIDENTIAL - HR ONLY” folders and “OPEN ACCESS” folders, and the assistant has a master key to everything, the labels stop protecting anything.
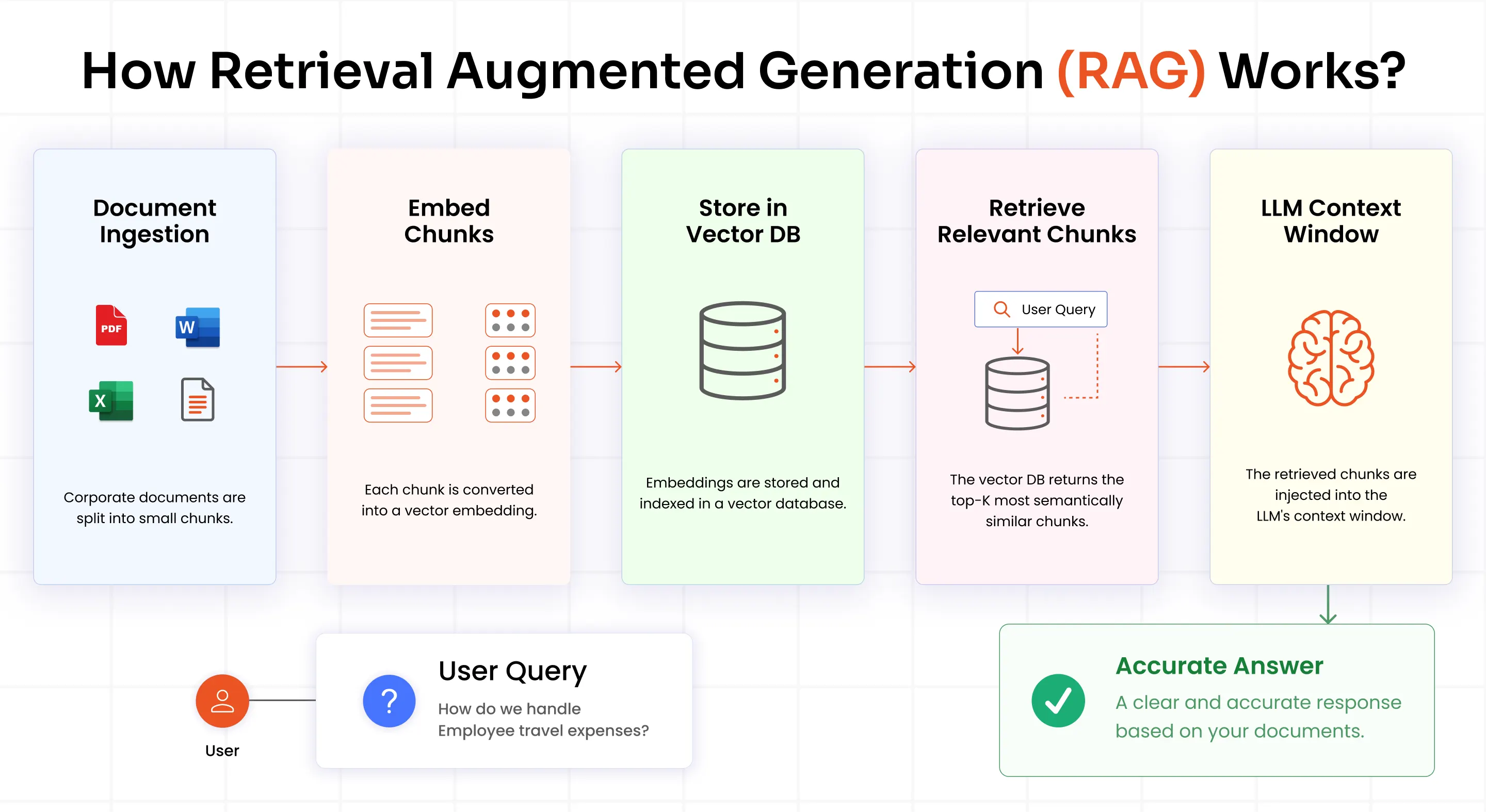
The technical workflow follows a specific, sequential path:
- Corporate documents are split into small chunks such as paragraphs, rows, or sections.
- Each chunk is converted into a vector embedding, which is a mathematical representation of its core meaning.
- These embeddings are stored and indexed within a vector database (Pinecone, Weaviate, pgvector) to enable fast lookups.
- When a user submits a query, that specific query is also converted into a vector embedding.
- The system queries the vector database to return the top-K most semantically similar chunks.
- Those specific chunks are injected into the LLM's context window as grounding context.
- The LLM generates a clear, natural language answer based strictly on the text chunks it was given.
This is where vector database authorization becomes critical.
Key Insight:
RAG by default optimizes for relevance, and “top-K similar” is not the same as “top-K authorized.”
Where the Data Leak Actually Happens — Retrieval, not Generation
Many security teams mistakenly assume the primary risk in AI deployment is the LLM hallucinating extra data or being bypassed via clever prompts. The actual security risk occurs much further upstream during the standard document gathering process.
To understand this, let us map out the exact progression of the salary spreadsheet leak:
- Step 1: User Query
An employee asks the interface: "What is the salary of an SDE 2 at our company?"
- Step 2: Vector Search
The pipeline embeds this query and searches the vector store. Because the compensation spreadsheet matches the query semantically, it ranks at the very top of the results.
- Step 3: Retrieval
The compensation rows containing data for all employees are pulled and passed to the LLM. The retrieval layer has no mechanism to check if the querying employee holds the rights to see this data; it only knows the data matches the topic.
- Step 4: Generation
The LLM receives the raw compensation data in its context window and accurately summarizes the text. The model is doing exactly what it was engineered to do.
- Step 5: Disclosure
The employee receives a detailed breakdown of colleague salaries. The data leak is complete, and it happened entirely within the parameters of normal system operations.
Critical Insight: Once data enters the LLM's context window, the security boundary is broken. A generation-layer filter cannot un-retrieve data that has already been exposed to the model. Authorization must happen before retrieval, not after.
That is the pivot point. If fine grained authorization is missing at retrieval time, the LLM is not the vulnerability. It is only the final step in exposing data that should never have been supplied in the first place.
What is Fine-Grained Authorization (FGA)?
When looking at corporate access control, stakeholders often ask: what is fine-grained authorization? It is an authorization model that makes access decisions at the level of individual resources, such as specific documents, rows, paragraphs, or data objects, rather than at the broad level of roles or resource types.
To fully understand what fine grained authorization is, it helps to contrast it directly with traditional models. Where standard role-based access control asks if a user has the general editor role, a fine-grained authorization model asks if this specific user has permission to access this specific document chunk, in this specific context, right now.
| Dimension | RBAC (Coarse-Grained) | FGA (Fine-Grained) |
|---|---|---|
| Access decision based on | General user role | User, resource, relationship, and context |
| Granularity | Resource type (e.g., "HR documents") | Individual resource (e.g., "Spreadsheet row 47") |
| Real-time context | No | Yes (risk score, time, device, delegation scope) |
| Dynamic permission changes | Manual, slow updates | Instant execution without data re-indexing |
| Suitable for RAG | No, the scope is too broad | Yes, allows per-chunk enforcement |
| Example | "HR team can read all HR docs" | "Employee can read their own row; managers can read their team's rows" |
Key Distinction: RBAC grants access to a broad category of data. FGA grants access to a specific piece of data, based entirely on the relationship between the user, the resource, and the current operational context.
In modern engineering architectures, OpenFGA serves as an excellent open-source implementation of Google's Zanzibar paper. Maintained by the CNCF, OpenFGA provides the core relationship-based authorization mechanics required to power fine-grained controls at scale. The miniOrange FGA implementation is built to be fully compatible with this specialized authorization model. (Source reference: openfga.dev)
Why RBAC Is Not Enough for RAG — And Where It Breaks
Evaluating FGA vs RBAC highlights why traditional coarse-grained security models fail when applied to generative AI pipelines. If you rely solely on standard RBAC, the access control evaluation for a document lookup looks simple:
- User Role: Employee
- Assigned Permission: Can read HR documents
- System Result: Access granted
The vulnerability here is that "HR documents" represents an incredibly broad category rather than a single specific file. Because every employee shares this general role-based access, the RAG pipeline treats the entire library as fair game during retrieval. This allows it to ingest sensitive salary rows along with standard holiday schedules.
Using fine-grained authorization on top of RBAC fixes this structural flaw by modeling explicit relationships at the object level:
- User Identification: Employee A
- Defined Relationship: Owns their personal record; reports to Manager X
- System Enforced Permission: Employee A can view their personal row. Manager X can view their direct reports' rows. HR can view all rows. No other paths exist.
This complex relationship graph is evaluated in real time for every individual chunk. The RAG pipeline queries the authorization service before including any data fragment in the final top-K context retrieval. If the querying user lacks a verified relationship to that chunk, the system filters it out completely.
Consider this analogy: RBAC is like giving an employee a broad floor pass to the entire corporate HR filing room. FGA functions like giving each employee a unique key that only opens their specific folder, while giving their manager a key that opens their team's files, but nothing else.
The Three Pillars of FGA for RAG Pipelines
Building a secure AI strategy requires implementing specialized fine grained authorization policies built across three distinct structural areas.
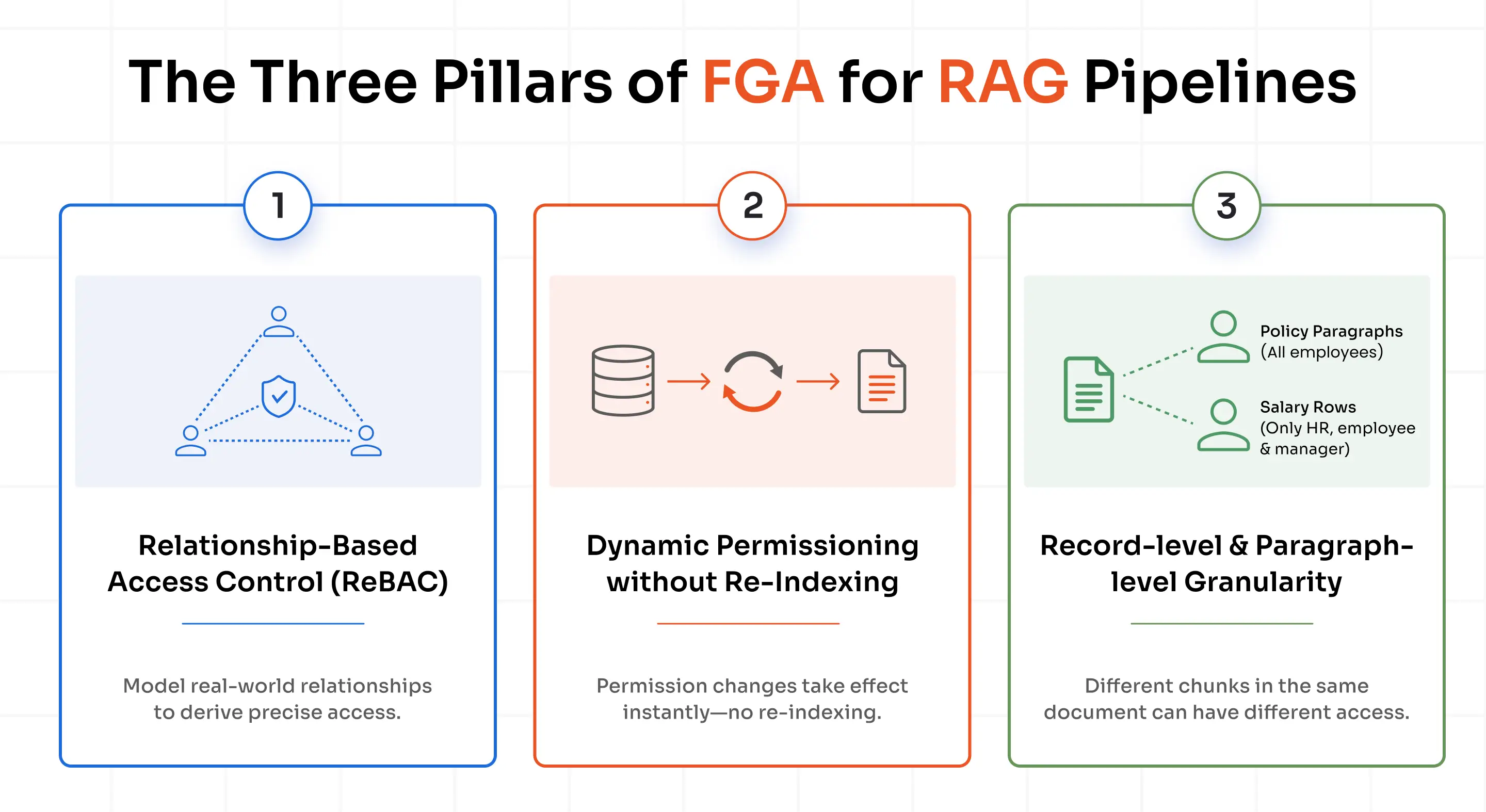
Pillar 1: Relationship-Based Access Control (ReBAC)
The relationship-based access control (ReBAC) framework is the specific authorization model that makes fine-grained control practical for complex corporate environments.
Instead of attempting to map flat permissions directly to thousands of users, ReBAC models access as a directed graph of real-world relationships connecting users, objects, and organizational groups.
In an RAG context, relationships look like this:
- An employee owns their salary row.
- A manager manages their direct reports.
- The manager inherits permission to read those reports’ rows.
- HR administers the compensation spreadsheet.
- HR inherits permission to read all rows.
When the RAG pipeline evaluates a query, it does not need to guess whether a chunk is safe. The authorization service checks whether the user has a valid relationship path to that chunk. If the answer is yes, the chunk can be retrieved. If not, it is excluded before it ever reaches the LLM.
That is the approach derived from Google's Zanzibar paper: permissions are derived from relationships, which makes them more precise and more scalable than flat access lists.
Pillar 2: Dynamic Permissioning without Re-Indexing
A major operational hurdle when securing modern vector databases is that re-embedding and re-indexing text data is computationally expensive and slow. Under older security configurations, changing who can access a document requires updating and re-processing metadata tags across the entire vector index.
FGA solves this by completely separating permission rules from the underlying vector data. Because access checks occur by querying the live relationship graph at retrieval time, permission adjustments take effect instantaneously.
That matters in everyday scenarios:
- An employee leaves the company, so their relationship to their salary row is removed. The next retrieval request blocks that row immediately.
- A manager gets promoted, so their direct-report relationships expand. Their visibility changes without touching the vector database.
- A document is reclassified as confidential, so the policy graph is updated. All future retrievals reflect the new rule instantly.
This is a major advantage because it keeps the retrieval layer aligned with current business rules instead of stale index metadata. No re-embedding is required. No re-indexing is required. The vector database remains intact, while the authorization layer enforces the new decision at query time.
For enterprise RAG, that separation is what makes the system maintainable.
Pillar 3: Record-level and paragraph-level granularity
Traditional authorization usually works at the file or folder level. That is too coarse for AI retrieval. A single document can contain a mix of safe, broadly shareable content and sensitive fragments that only a few people should see. FGA solves that by treating fragments as first-class access objects.
Take a compensation policy document. It may include the company’s salary philosophy, which is fine for all employees to read. In the same file, it may also contain exact salary rows by employee name and level, which should be visible only to HR, the employee themselves, and their manager.
With fine-grained enforcement, those chunks can carry different permissions inside the same source document:
- Policy paragraphs: accessible to all employees
- Salary rows: accessible only to HR, the employee, and the manager
This is the practical value of fine-grained access control in AI implementation. The RAG system can still answer useful questions about policy, benefits, or compensation bands without exposing private rows. The LLM never sees unauthorized chunks, so it cannot reveal them, quote them, or infer them in its response.
That is the difference between safe context retrieval and accidental disclosure.
The AI Agent Identity Problem — Who is Actually Making the Retrieval Request?
So far, we have discussed fine-grained authorization (FGA) from the perspective of a human user querying a RAG system. That is only part of the security model.
In an agentic workflow, the real requester may be a non-human actor, such as an LLM or autonomous AI agent that can search documents, call tools, chain tasks, and continue retrieving data across multiple steps.
That introduces a broader AI agent identity challenge. The system is no longer answering only, “Does this user have access?” It also has to answer, “What is this agent allowed to do on its own?” and “What authority did the human user delegate to it?” Those two questions are not the same, and treating them as the same creates unnecessary exposure.
The correct pattern is delegated authorization, also known as “on-behalf-of” authorization. The agent should not receive a broad token that unlocks the entire vector database. Instead, the system should propagate both identities: the agent's own identity and the delegating user's identity. This is a critical requirement for implementing fine-grained access control in AI systems securely.
The authorization decision is then made against the intersection of those two permission scopes. In practice, that means the agent can retrieve only what both identities are permitted to access. This approach extends FGA for RAG beyond human users and ensures that autonomous agents remain bound by the same authorization boundaries as the people they represent.
"An AI agent should never have more access than the human who invoked it. Delegated authorization enforces this at the retrieval layer."
What a Secure RAG Architecture Looks Like End-to-End
A secure RAG architecture relies on three distinct controls working together: authentication, authorization, and auditability. If any one of these layers is missing, sensitive data can still find its way into the LLM's context window.
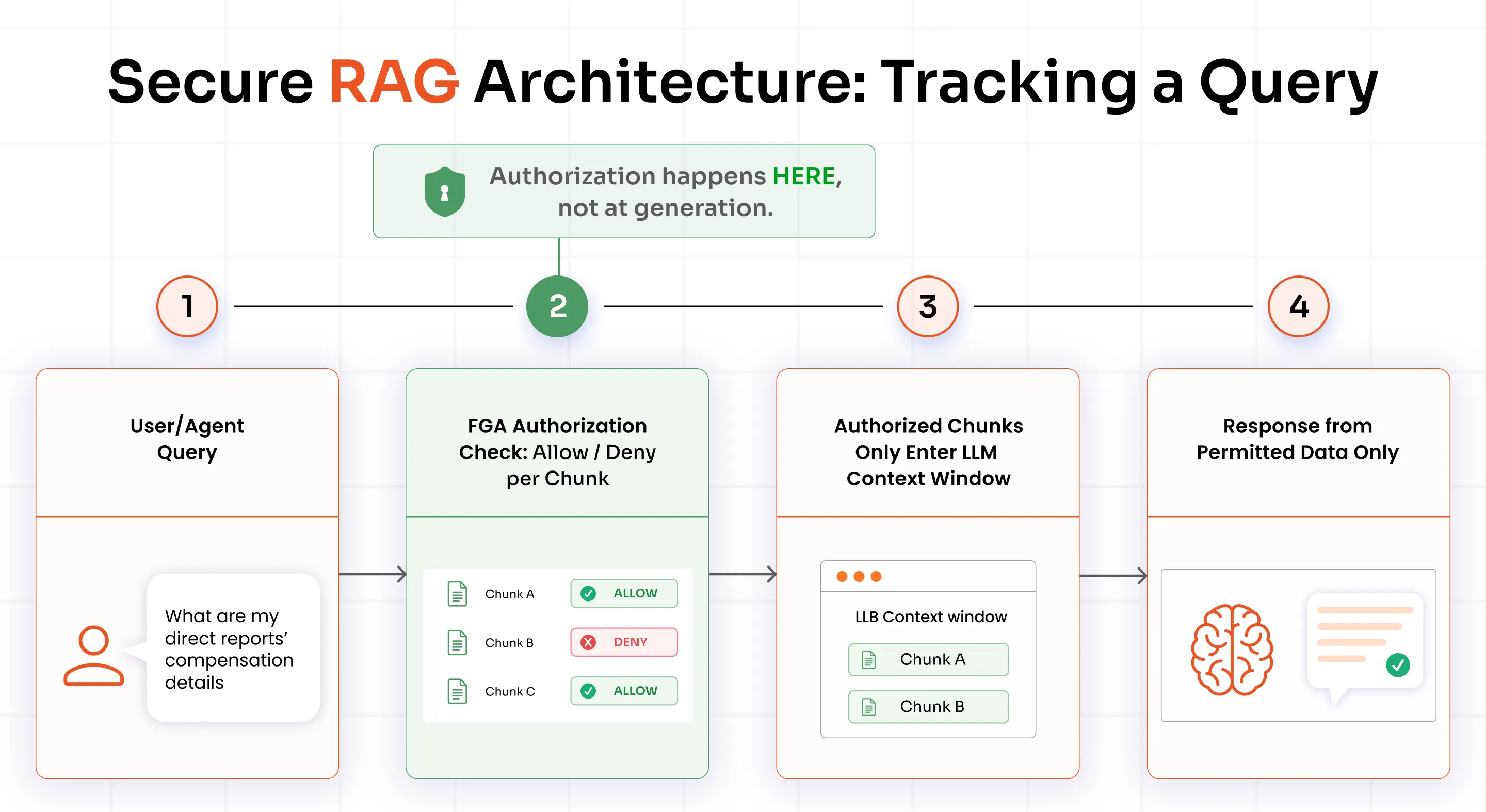
1. Authentication: Every retrieval request must carry a verified identity
Every retrieval request should be tied to a verified identity, whether the requester is a human user, an AI agent, or both. Long-lived API keys and static service accounts are high-risk patterns because they provide broad, persistent access that is disconnected from the identity behind the request.
Modern RAG architectures replace static credentials with workload identity and short-lived credentials. Technologies such as OAuth 2.1, SPIFFE/SVID, and mTLS allow agents to authenticate securely and obtain ephemeral tokens scoped to a specific session.
This enables the system to evaluate both the agent's identity and the delegating user's identity when making access decisions, ensuring that authorization remains tied to the actual requester rather than a generic service account.
2. Fine-Grained Authorization at retrieval time
Authentication answers the question, "Who is making the request?" The FGA service answers a different question: "What is this identity allowed to access?"
Before any document chunk enters the LLM's context window, the RAG pipeline sends three inputs to the FGA authorization service:
- The requester's identity
- The candidate chunk's resource ID
- The requested action (typically read)
The service evaluates the relevant relationships and fine-grained authorization policies associated with that resource and returns an allow or deny decision for each chunk. Only authorized chunks proceed to the LLM.
This pre-retrieval authorization check is the most important security control in the architecture. It is not a prompt filter, output filter, or generation guardrail. It is a hard boundary that determines which data the model is allowed to see in the first place.
3. Audit logging: Chain of custody for every context chunk
Every authorization decision should be recorded. That includes every chunk that was retrieved, every chunk that was blocked, and the identities involved in each decision.
This creates a complete chain of custody for the data used to ground AI responses. Security teams can trace exactly which chunks entered the context window, why access was granted, and which identity initiated the request.
As organizations adopt AI across regulated environments, this level of visibility becomes increasingly important for demonstrating compliance with GDPR, HIPAA, SOC 2, and India's DPDPA. The goal is no longer just understanding what the AI said. Organizations must also be able to prove which specific data sources contributed to that response.
How miniOrange Implements FGA for RAG Pipelines
If you are evaluating the top fine-grained authorization solutions in 2026, miniOrange implements FGA for RAG pipelines through a combination of relationship-based authorization policies and real-time permission evaluation at the retrieval layer.
The approach is designed to address the core challenge discussed throughout this article: ensuring that relevance does not override authorization.
Key capabilities include:
- Per-document and per-chunk authorization that evaluates permissions at the individual document fragment level rather than treating an entire file or folder as a single access boundary.
- ReBAC policy modeling that represents relationships between users, groups, roles, and resources as a graph, enabling permission inheritance for common business scenarios such as manager-to-team access.
- Real-time permission evaluation where authorization decisions are made for every query and every candidate chunk before retrieval results are passed to the model.
- Delegated authorization for AI agents, supporting broader AI agent authorization requirements by enforcing the intersection of user permissions and agent permissions during retrieval.
- Instant permission revocation that updates access decisions immediately without requiring vector database re-indexing or document reprocessing.
- Compliance audit trails that record the requesting identity, resource identifier, authorization outcome, and timestamp for every retrieval decision.
By combining authentication, relationship-aware authorization, and retrieval-time enforcement, miniOrange helps organizations implement fine-grained access control for AI systems while reducing the risk of unauthorized data exposure in enterprise RAG environments.
The bottom line: relevance is not permission
RAG systems deliver value by finding the most relevant information for a given query. The problem is that relevance and authorization are two completely different concepts. A compensation spreadsheet may be highly relevant to a salary-related question, but that does not mean every employee should be able to retrieve it.
This is where fine grained authorization becomes essential. By evaluating permissions before retrieval, FGA ensures that only authorized document chunks enter the LLM's context window. Combined with ReBAC, organizations can enforce access policies based on real-world relationships, while dynamic permissioning ensures changes are reflected immediately without disrupting the underlying vector infrastructure.
The salary spreadsheet leak scenario is not an isolated system glitch; it is the natural outcome of a RAG system that retrieves data based solely on semantic similarity. As enterprises deploy AI across increasingly sensitive datasets, fine-grained access control in AI architectures become a foundational security requirement rather than an optional enhancement.
FAQs
What is the difference between FGA and RBAC?
RBAC grants permissions based on broad roles, such as Employee, Manager, or HR Administrator. That works well when everyone in a role needs the same level of access. RAG systems create a different challenge because access decisions often need to be made at the document, record, or chunk level. FGA (fine grained authorization) evaluates whether a specific user can access a specific resource based on relationships and context. For example, a manager may be allowed to view salary information for direct reports but not for employees in other teams. This makes FGA significantly more effective than RBAC for controlling retrieval in AI systems.
What is ReBAC (Relationship-Based Access Control)?
Relationship-Based Access Control (ReBAC) is the authorization model that powers many modern fine grained authorization systems. Instead of assigning permissions through static roles or access lists, ReBAC determines access based on relationships between users and resources. For example, an employee may own a document, while their manager gains access through the management relationship. This approach makes it easier to model real-world access patterns that change over time. For RAG systems, ReBAC is particularly effective because document ownership, reporting structures, project memberships, and sharing rules are often too complex to be represented through traditional RBAC alone.
Does FGA slow down RAG retrieval?
When implemented correctly, an enterprise FGA service adds minimal latency, typically running in under 5 milliseconds per query. The authorization check typically runs alongside or immediately after the vector similarity search and determines which chunks are eligible to enter the LLM's context window. While there is a small overhead, it is negligible compared to the security and compliance risks of exposing sensitive information through unauthorized retrieval.
Does FGA require re-indexing the vector database when permissions change?
No. One of the biggest advantages of FGA is that permissions are managed separately from the vector embeddings themselves. When a user's access changes because of a promotion, project reassignment, or departure from the organization, only the relationship graph needs to be updated. The documents, embeddings, and vector index remain unchanged. The next retrieval request automatically reflects the updated permissions. This allows organizations to enforce real-time access control without the operational burden of re-indexing or re-embedding data whenever authorization rules change.
What is the difference between pre-retrieval and post-generation authorization filtering?
Pre-retrieval authorization applies access controls before document chunks are passed to the LLM. If a user is not authorized to access a chunk, it never enters the model's context window. Post-generation filtering takes a different approach by inspecting the model's response after it has already been generated. The challenge is that the LLM may have already used unauthorized information to shape its answer, even if the original content is later removed. For this reason, fine-grained authorization is most effective when enforced pre-retrieval, before any sensitive data reaches the model.
What compliance frameworks require FGA for RAG?
No major compliance framework explicitly mandates fine-grained authorization for RAG systems. However, regulations such as GDPR, HIPAA, SOC 2, and India's DPDPA all require organizations to implement appropriate access controls and limit access to sensitive information on a need-to-know basis. A RAG system that retrieves data solely based on relevance can expose information beyond a user's authorized scope. FGA helps address this risk by enforcing access decisions at the document, record, and chunk level, supporting the data minimization and access control principles required by these frameworks.



Leave a Comment